Chatbot đã không còn xa lạ hiện nay đối với người dùng Internet nếu muốn hỏi-đáp về một lĩnh vực gì đó. Tuy nhiên, để tạo ra Chatbot bằng Python, hẳn nhiều người còn chưa biết làm. Hãy cùng tìm hiểu nhé!
Chatbot là gì?
Chatbot trong Python là một phần mềm sử dụng Trí tuệ nhân tạo (AI) để nói chuyện tương tác với mọi người bằng ngôn ngữ có thể văn bản hoặc giọng nói. Hầu hết, những chatbot này nói chuyện bằng âm thanh hoặc văn bản và chúng có thể dễ dàng bắt chước ngôn ngữ của con người để nói chuyện với mọi người theo cách có vẻ tự nhiên như con người.
Việc đào tạo máy học dựa trên quy tắc dạy cho chatbot trả lời các câu hỏi dựa trên một bộ quy tắc được đưa ra khi bắt đầu huấn luyện. Những quy tắc này có thể rất đơn giản hoặc rất khó hiểu. Chatbot dựa trên quy tắc rất giỏi trong việc trả lời các câu hỏi đơn giản, nhưng chúng thường không thể xử lý các câu hỏi hoặc yêu cầu phức tạp hơn.

Chatbot trong thế hệ ngày nay
Ngày nay, chúng ta có Chatbot thông minh được hỗ trợ bởi AI và sử dụng xử lý ngôn ngữ tự nhiên (NLP) để hiểu lệnh văn bản và giọng nói từ con người cũng như học hỏi từ các tương tác trước đây của họ.
Chatbots đã trở thành một cách tiêu chuẩn để các công ty và thương hiệu có sự hiện diện trực tuyến nói chuyện với khách hàng của họ (nền tảng trang web và mạng xã hội).
Chatbot được phát triển dựa trên Python là một công cụ hữu ích vì chúng cho phép thương hiệu và khách hàng nói chuyện với nhau ngay lập tức. Hãy nghĩ về Siri của Apple, Alexa của Amazon và Cortana của Microsoft. Sở dĩ trong bài viết tôi chọn ngôn ngữ Python để xây dựng demo ứng dụng nhỏ này để tận dụng bộ thư viện học máy Machines Learning (ML)
Lợi ích Chatbot cho doanh nghiệp
Khi nói đến việc tạo mối quan hệ tốt với khách hàng, chatbot có thể là một công cụ rất hữu ích. Doanh nghiệp của bạn có thể sử dụng nó để xây dựng kết nối mạnh mẽ với khách truy cập trang web bằng cách tìm hiểu và nói chuyện với họ. Bằng cách sử dụng chatbot, bạn không chỉ có thể đạt được mục tiêu tiếp thị của mình mà còn có thể bán được nhiều hàng hơn và cung cấp dịch vụ khách hàng tốt hơn.
Có nhiều cách chatbot có thể cải thiện cách bạn nói chuyện với khách hàng và giúp doanh nghiệp của bạn phát triển:
- Tăng sự tương tác của khách hàng
- Cải thiện việc tạo khách hàng tiềm năng
- Giảm chi phí dịch vụ khách hàng
- Giám sát dữ liệu người tiêu dùng để hiểu rõ hơn
- Đưa ra chiến lược tiếp thị đàm thoại
- Cân bằng tự động hóa với sự tiếp xúc của con người
- Đáp ứng mong đợi của khách hàng
- Đạt được khả năng mở rộng hỗ trợ
- Hợp lý hóa quy trình giới thiệu khách hàng của bạn
- Làm cho hành trình của khách hàng suôn sẻ hơn
Làm cách nào để tạo Chatbot bằng Python?
Chúng ta sẽ thực hiện từng bước quá trình xây dựng chatbot Python.
Chúng ta sẽ sử dụng các kỹ thuật học sâu (Deep Learning) để xây dựng một chatbot. Chatbot sẽ học từ tập dữ liệu có các danh mục (mục đích sử dụng), mẫu và câu trả lời.
Chúng ta sử dụng mạng thần kinh tái phát đặc biệt (LSTM) để tìm ra danh mục nào phù hợp với tin nhắn của người dùng và sau đó tôi chọn một phản hồi ngẫu nhiên từ danh sách phản hồi.
Bây giờ chúng ta sẽ sử dụng Python để xây dựng chatbot, nhưng trước tiên hãy xem cách sắp xếp các tệp và loại tệp chúng ta sẽ tạo:
- Intents.json – Tệp dữ liệu có các mẫu và phản hồi được xác định trước.
- train_chatbot.py – Trong tệp Python này, chúng ta viết một tập lệnh để xây dựng mô hình và huấn luyện chatbot của mình.
- Words.pkl – Đây là một tệp mà trong đó chúng tôi lưu trữ các từ đối tượng Python chứa danh sách từ vựng của chúng ta.
- Class.pkl – Tệp chọn lớp chứa danh sách các danh mục các từ được lưu lại trong quá trình học.
- Chatbot_model.h5 – Đây là mô hình được đào tạo chứa thông tin về mô hình và có trọng số của các nơ-ron.
- Chatgui.py – Đây là tập lệnh Python mà chúng ta đã triển khai GUI cho chatbot của mình. Người dùng có thể dễ dàng tương tác với bot.
Các bước trong mô hình đơn giản để tạo Chatbot bằng Python từ đầu
- Bước 1: Nhập và tải file dữ liệu
Trước tiên, chúng ta cần tạo một tệp có tên train_chatbot.py. Đây là file cần thiết mà chatbot của chúng ta cần và thiết lập các biến mà chúng ta sẽ sử dụng trong dự án Python của mình.train_chatbot.py
Tệp dữ liệu có định dạng JSON nên chúng ta đã sử dụng tệp này để đọc tệp bằng Python.json packageJSON
|
Code mẫu import nltk from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() import json import pickle import numpy as np from keras.models import Sequential from keras.layers import Dense, Activation, Dropout from keras.optimizers import SGD from tensorflow.keras.optimizers import SGD import random words=[] classes = [] documents = [] ignore_words = [‘?’, ‘!’] data_file = open(‘intents.json’).read() intents = json.loads(data_file) |
- Bước 2: Dữ liệu tiền xử lý
Trước khi có thể tạo mô hình học máy hoặc học sâu từ dữ liệu văn bản ban đầu, chúng ta phải xử lý dữ liệu theo nhiều cách khác nhau mà chúng ta sử dụng thư viện Xử lý ngôn ngữ tự nhiên (nltk). Tùy theo nhu cầu mà chúng ta phải sử dụng các thao tác khác nhau để xử lý trước dữ liệu.
Mã hóa dữ liệu văn bản là điều đầu tiên và cơ bản nhất bạn có thể làm với nó. Tokenizing là quá trình chia văn bản thành nhiều phần nhỏ, chẳng hạn như các từ.
Ở đây, chúng ta xem xét các mẫu, sử dụng chức năng chia câu thành các từ và thêm từng từ vào danh sách từ. Chúng ta cũng lập danh sách các lớp mà thẻ của chúng tôi thuộc về nltk.word_tokenize()
|
Code mẫu for intent in intents[‘intents’]: for pattern in intent[‘patterns’]: #tokenize each word w = nltk.word_tokenize(pattern) words.extend(w) #add documents in the corpus documents.append((w, intent[‘tag’])) # add to our classes list if intent[‘tag’] not in classes: classes.append(intent[‘tag’]) |
Bây giờ, chúng ta sẽ tìm hiểu nghĩa của từng từ và loại bỏ bất kỳ từ nào đã có trong danh sách. Lemmatizing là quá trình thay đổi một từ thành dạng bổ đề của nó và sau đó tạo một tệp Pick để lưu trữ các đối tượng Python mà chúng ta sẽ sử dụng khi dự đoán.
|
Code mẫu # tách, chia nhỏ các từ và thực hiện xử lý tránh trùng lặp các từ words = [lemmatizer.lemmatize(w.lower()) for w in words if w not in ignore_words] words = sorted(list(set(words))) # lớp sắp xếp từ classes = sorted(list(set(classes))) # documents = sự kết hợp giữa mẫu và dự kiến ý định ngữ nghĩa của từ print (len(documents), “documents”) # classes = ý định ngữ nghĩa của từ print (len(classes), “classes”, classes) # words = tất cả các từ, từ vựng ngữ nghĩa của từ print (len(words), “unique lemmatized words”, words) pickle.dump(words,open(‘words.pkl’,’wb’)) pickle.dump(classes,open(‘classes.pkl’,’wb’)) |
- Bước 3: Tạo dữ liệu đào tạo và kiểm tra dữ liệu huấn luyện
Bây giờ, chúng ta sẽ tạo dữ liệu huấn luyện, bao gồm cả đầu vào và đầu ra. Mẫu sẽ là đầu vào của chúng ta và lớp mà mẫu sẽ là đầu ra của chúng ta. Nhưng máy tính không đọc được chữ nên chúng ta sẽ biến chữ thành số.
|
Code mẫu # Tạo dữ liệu huấn luyện training = [] output_empty = [0] * len(classes) # Tập huấn luyện cho từng từ trong câu for doc in documents: # khởi tạo từ bag = [] # list các từ được mã hóa trong mẫu pattern_words = doc[0] pattern_words = [lemmatizer.lemmatize(word.lower()) for word in pattern_words] # tạo mảng từ của chúng ta bằng 1, nếu tìm thấy từ khớp trong mẫu hiện tại for w in words: bag.append(1) if w in pattern_words else bag.append(0) # đầu ra là ‘0’ cho mỗi thẻ và ‘1’ cho thẻ hiện tại (cho mỗi mẫu) (for each pattern) output_row = list(output_empty) output_row[classes.index(doc[1])] = 1 training.append([bag, output_row]) # xáo trộn các tính năng của chúng tôi và biến thành np.array random.shuffle(training) training = np.array(training) # tạo danh sách đào tạo và kiểm tra. X – mẫu, Y – ý định train_x = list(training[:,0]) train_y = list(training[:,1]) print(“Training data created”) |
- Bước 4: Xây dựng mô hình
Bây giờ dữ liệu đào tạo của chúng ta đã sẵn sàng, chúng ta sẽ xây dựng mạng lưới thần kinh với mô hình máy học sâu 3 lớp. Chúng ta thực hiện việc này bằng Keras API tuần tự. Sau khi huấn luyện mô hình trong 500 lần lặp, nó chính xác 100%. Hãy đặt tên tập tin là “ chatbot model.h5” và lưu nó.
|
Code mẫu # Tạo mô hình – 3 lớp. Lớp đầu tiên 128 nơ-ron, lớp thứ hai 64 nơ-ron và lớp đầu ra thứ 3 chứa số lượng nơ-ron với softmax là số lượng ý định để dự đoán. model = Sequential() model.add(Dense(128, input_shape=(len(train_x[0]),), activation=’relu’)) model.add(Dropout(0.5)) model.add(Dense(64, activation=’relu’)) model.add(Dropout(0.5)) model.add(Dense(len(train_y[0]), activation=’softmax’)) # Biên dịch mô hình. Giảm độ dốc sự sai lệch ngẫu nhiên với độ dốc tăng tốc Nesterov cho kết quả tốt cho mô hình huấn luyện này sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=’categorical_crossentropy’,optimizer=sgd, metrics=[‘accuracy’]) #Tránh lắp quá khớp với mô hình hist = model.fit(np.array(train_x), np.array(train_y), epochs=500, batch_size=5, verbose=1) model.save(‘chatbot_model.h5’, hist) print(“model created”) |
- Bước 5: Dự đoán phản hồi (Giao diện người dùng đồ họa (GUI))
Để dự đoán câu và nhận được phản hồi từ người dùng, chúng ta hãy tạo một tệp mới có tên chatapp.py
Chúng ta sẽ tải mô hình đã được đào tạo và sau đó sử dụng giao diện người dùng đồ họa để dự đoán phản hồi của bot. Mô hình sẽ chỉ cho chúng ta biết nó thuộc lớp nào, vì vậy chúng ta sẽ tạo một số hàm để tìm ra lớp đó và sau đó chọn một phản hồi ngẫu nhiên từ danh sách phản hồi. Một lần nữa, chúng ta tải các tệp ‘ words.pkl’ và ‘ classes.pkl ‘ mà chúng ta đã tạo khi huấn luyện mô hình của mình:
|
Code mẫu import nltk from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() import pickle import numpy as np from keras.models import load_model model = load_model(‘chatbot_model.h5’) import json import random intents = json.loads(open(‘intents.json’).read()) words = pickle.load(open(‘words.pkl’,’rb’)) classes = pickle.load(open(‘classes.pkl’,’rb’)) |
Để dự đoán lớp huần luyện học máy, chúng ta sẽ phải đưa ra thông tin đầu vào giống như cách chúng ta đã làm trong quá trình đào tạo. Vì vậy, chúng ta sẽ tạo một số hàm thực hiện tiền xử lý trên văn bản và sau đó đoán lớp.
|
Code mẫu def clean_up_sentence(sentence): # Mã hóa mẫu = chia các từ thành phần tử mảng sentence_words = nltk.word_tokenize(sentence) # rút gọn từ sentence_words = [lemmatizer.lemmatize(word.lower()) for word in sentence_words] return sentence_words # Trả về mảng từ: 0 hoặc 1 cho mỗi từ trong bộ từ tồn tại trong câu def bow(sentence, words, show_details=True): # Mã hóa mẫu sentence_words = clean_up_sentence(sentence) # Từ mẫu trong ma trận N từ vựng bag = [0]*len(words) for s in sentence_words: for i,w in enumerate(words): if w == s: # Gán 1 nếu từ có trong thư viện từ bag[i] = 1 if show_details: print (“found in bag: %s” % w) return(np.array(bag)) def predict_class(sentence, model): # Lọc các từ dự đoàn ở ngưỡng chính xác p = bow(sentence, words,show_details=False) res = model.predict(np.array([p]))[0] ERROR_THRESHOLD = 0.25 results = [[i,r] for i,r in enumerate(res) if r>ERROR_THRESHOLD] # Sắp xếp theo cường độ sác xuất tốt results.sort(key=lambda x: x[1], reverse=True) return_list = [] for r in results: return_list.append({“intent”: classes[r[0]], “probability”: str(r[1])}) return return_list |
Sau khi dự đoán lớp, chúng ta sẽ nhận được phản hồi ngẫu nhiên từ danh sách các ý định.
|
Code mẫu def getResponse(ints, intents_json): tag = ints[0][‘intent’] list_of_intents = intents_json[‘intents’] for i in list_of_intents: if(i[‘tag’]== tag): result = random.choice(i[‘responses’]) break return result def chatbot_response(text): ints = predict_class(text, model) res = getResponse(ints, intents) return res |
Bây giờ, chúng ta sẽ tạo giao diện đồ họa người dùng (GUI). Hãy sử dụng thư viện Tkinter, thư viện này có rất nhiều thư viện GUI hữu ích khác.
Chúng ta sẽ nhận tin nhắn của người dùng và sử dụng các chức năng trợ giúp mà chúng ta đã thực hiện để nhận câu trả lời từ bot và hiển thị nó trên GUI. Đây là mã nguồn đầy đủ của GUI.
|
#Creating GUI with tkinter import tkinter from tkinter import * def send(): msg = EntryBox.get(“1.0”,’end-1c’).strip() EntryBox.delete(“0.0”,END) if msg != ”: ChatLog.config(state=NORMAL) ChatLog.insert(END, “You: ” + msg + ‘\n\n’) ChatLog.config(foreground=”#442265″, font=(“Verdana”, 12 )) res = chatbot_response(msg) ChatLog.insert(END, “Bot: ” + res + ‘\n\n’) ChatLog.config(state=DISABLED) ChatLog.yview(END) base = Tk() base.title(“CHAT BOT”) base.geometry(“400×500”) base.resizable(width=FALSE, height=FALSE) #Create Chat window ChatLog = Text(base, bd=0, bg=”white”, height=”8″, width=”50″, font=”Arial”,) ChatLog.config(state=DISABLED) #Bind scrollbar to Chat window scrollbar = Scrollbar(base, command=ChatLog.yview, cursor=”heart”) ChatLog[‘yscrollcommand’] = scrollbar.set #Create Button to send message SendButton = Button(base, font=(“Verdana”,12,’bold’), text=”Send”, width=”12″, height=5, bd=0, bg=”#32de97″, activebackground=”#3c9d9b”,fg=’#ffffff’, command= send ) #Create the box to enter message EntryBox = Text(base, bd=0, bg=”white”,width=”29″, height=”5″, font=”Arial”) #EntryBox.bind(“<Return>”, send) #Place all components on the screen scrollbar.place(x=376,y=6, height=386) ChatLog.place(x=6,y=6, height=386, width=370) EntryBox.place(x=128, y=401, height=90, width=265) SendButton.place(x=6, y=401, height=90) base.mainloop() |
- Bước 6: Chạy Chatbot Python
Để chạy chatbot, chúng tôi có hai tệp chính; train_chatbot.py và chatapp.py.
Đầu tiên, chúng ta huấn luyện mô hình bằng lệnh trong Terminal:
| python train_chatbot.py |
Nếu chương trình Python đã cài đặt đủ thư viện và môi trường chạy biên dịch cũng như không tìm thấy bất kỳ sai sót nào trong quá trình đào tạo thì mô hình đã được thực hiện tốt. Sau đó, chúng tôi chạy tệp thứ hai để khởi động ứng dụng.
|
python chatgui.py |
Trong vài giây, chương trình sẽ mở một cửa sổ GUI. Với GUI, việc nói chuyện với bot thật đơn giản.
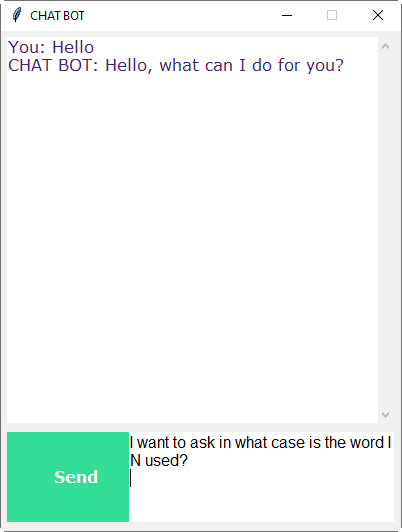
Trong bài viết này, chúng ta đã tìm hiểu về bước về cách tạo Chatbot đơn giả sử dụng thư viện máy học sâu xử lý ngôn ngữ tự nhiên (NLTK) trong Hy vọng bài viết này có thể giúp các bạn sinh viên rất nhiều để nâng cao và phát triển các kỹ năng cũng như ý tưởng logic, điều quan trọng trong việc thực hành lập trình ngôn ngữ lập trình python.
Bộ môn Ứng dụng phần mềm
Trường Cao đẳng FPT Mạng cá cược bóng đá
cơ sở Hà Nội